A Quantitative Comparison of Serving Platforms for Neural Networks
Choosing the suitable method of production serving your neural network model is one of the most critical decisions. There are many options available on how to serve a model, and of course, there is also dependency on neural network frameworks. Some serving tools are model-agnostic, yet in most settings, it is beneficial to use the native serving tool that comes with the framework of your choosing. Here in Biano we struggled to select the most suitable framework for our neural networks and select the best serving tool for our purposes. We use about ten big neural nets in production (ranging from classic image classification to autoencoders and some NLP) and hundreds of tiny models created on the fly by our content team. These miniature models are typically used once only to classify fine details in certain products (such as whether given chairs have armrests or not). Running many neural network models at the same time is not simple. One option for how to do it is to use some serving method. Available serving systems depend on the selected framework, of course. We consider only TensorFlow and PyTorch as these are the two frameworks we have been using from the beginning. Both of them have their native serving system. After some thought, we decided to compare PyTorch’s TorchServe with TensorFlow’s Serving with NVIDIA’s Triton™ Inference Server, which supports multiple deep-learning frameworks like TensorRT, PyTorch, TensorFlow, and many more. As the test case, we went with the simple image classification on the ImageNet dataset. The model we use is just simple ResNet-50 because it has reference implementation in both PyTorch and Tensorflow, and both frameworks provide a pretrained model for ImageNet classification. Also, the ResNet architecture is very well known and studied, and most of the field is familiar with it. As in production, it is crucial to have accurate results and get the results with minimal latency. Last but not least, we need the serving tool to be as stable as possible (i.e., be robust against corrupted input data and such unfortunate situations). We have measured performance, stability, and latency.
Existing Serving Methods
In this section, we provide an overview of currently available and widely used serving tools. Most of these tools support deep-learning frameworks and other popular machine learning frameworks such as Scikit-learn or SpaCy, for example. This being said, it only emphasizes the importance of choosing the correct serving tool for your mission’s needs. Before introducing serving tools, the go-to method was serving using a custom Flask wrapper around your model (or models). This solution is elegant, yet it has many drawbacks such as very low flexibility, bad performance unless optimized, poor scalability, and way too much hassle to maintain. Using serving tools has its perks in deploying them once in your cloud solution and practically forgetting about them (unless you need to update them).
TorchServe (documentation)
TorchServe is a flexible and easy-to-use tool for serving PyTorch models created by Facebook. It’s an open-source framework enabling quick and easy deployment of both formats of models produced by PyTorch. TorchServe provides an easy tool for packaging models providing easy versioning and both already-made handlers as well as custom handlers written in Python. It is able to serve multiple models in one instance and is very easy to scale. Provides a straightforward REST API for both model inference and management and provides metrics that can be easily loaded into your Prometheus solution. It supports not only HTTP API but also gRPC API. It supports batching; however, it needs to be explicitly enabled through the Management API and can’t be enabled using command-line options (as of July 2021). It is still in the development stage, yet it handles production usage very well.
TensorFlow Serving (documentation)
TensorFlow Serving is a flexible, high-performance serving system for machine learning models designed for production environments. Created by Google, it is one of the first serving tools ever to exist. Flexible, high-performance serving system for machine learning models, designed for production environments. It supports both HTTP and gRPC APIs for both inference and management. It can serve multiple models or multiple versions of the same model simultaneously, which could be beneficial for new versions and A/B testing experimental models. Unlike TorchServe, it can serve models without Python handlers.
Triton™ Inference Server (documentation)
NVIDIA’s Triton Inference Server provides a cloud and edge inferencing solution optimized for both CPUs and GPUs. Supports REST and GRPC APIs that allow remote clients to request inferencing for any model being managed by the server. On edge deployment, Triton is available as a shared library with a C API that allows the full functionality of Triton to be included directly within an application. Triton supports multiple deep-learning frameworks (TensorRT, TensorFlow GraphDef, TensorFlow SavedModel, ONNX, and PyTorch TorchScript) and even vanilla Python scripts or C++ applications. It supports ensembles of models, which are pipelines of one or more models, each possible using a different framework. Provides metrics indicating GPU utilization, server throughput, and server latency in Prometheus data format.
Multi Model Server (documentation)
Created by Amazon Web Services - Labs, Multi Model Server is a flexible and easy-to-use tool for serving deep learning models trained using any ML/DL framework. It is optimized for running on AWS’s infrastructure, but it can run basically on any * NIX-based system (Windows support is still experimental). It is heavily based on TorchServe, even to such an extent that it supports the same frameworks (however, it also supports the MXNet framework) and uses the same model packaging tool. Just like the others, it also provides REST API for both inference and management of the models.
BentoML (documentation)
BentoML is a flexible, high-performance framework for serving, managing, and deploying machine learning models. It’s a tool that helps build and ship prediction services instead of uploading pickled model files or Protobuf files to a server. It tries to bridge the gap between data science and DevOps to deliver prediction services quickly, repeatable, and scalable. Support multiple ML frameworks, including PyTorch, TensorFlow, Scikit-Learn, XGBoost, and many more. It provides a containerized model server for production deployment with Docker, Kubernetes, OpenShift, AWS ECS, Azure, GCP GKE, etc. Works as a central hub for managing models and deployment processes via Web UI and APIs. Currently, it is one of the most widely used serving tools.
Cortex (documentation)
Cortex is specifically designed for running on AWS infrastructure and aims to deploy, manage, and scale containers without worrying about Kubernetes. It lets you deploy all sorts of ML models, not only deep-learning ones. Cortex is built on top of Kubernetes to support large-scale machine learning workloads. It provides automatic scaling, AWS spot instances, and multiple environments to create multiple clusters with different configurations. It can respond to requests in real-time and autoscale based on in-flight request volumes and even process requests asynchronously and in batches.
Test Environment and Setup
We used TensorFlow Serving in production for some time. It works very well, but we need to deploy some PyTorch models too. That was the main reason to investigate other serving tools. Finally, we decided to compare TensorFlow Serving, Torchserve, and Triton Inference server performance and reliability. Our goal was to measure and compare selected serving tools and provide a complete code and procedure to reproduce our results. We focused on the REST API interface of these tree serving methods. Each of the servings has a slightly different inference endpoint. TensorFlow serving expects a NumPy array of all three RGB channels of the image transformed into a JSON object. Therefore the request payload is quite large, and it requires non-trivial processing time for data deserialization. TorchServe bet all on binary data, and it was worth it. Inference endpoint in Torchserve is, by default, a simple post that expects HTTP uploaded data as an input. It makes Torchserve the simplest method to call the inference. Triton Inference Server needs to be called by a special client (it supports multiple languages such as Go, C++, Java, and Python, available from here). We have created a middleware API around serving methods to unify the interface call for all serving methods for obvious reasons. It simplifies load testing configuration, and it is a more production-like configuration. Our middleware has the infer endpoint, which corresponds to Torchserve API.
We designed the infrastructure within the AWS ecosystem. We tried to keep it as simple as possible, so we used two servers. The first node with GPU was for an observed serving method. The second node was for middleware API and the load testing tool. We used g4dn.xlarge with Deep Learning AMI from AWS for the serving machine and c5.xlarge with standard Ubuntu 20.04 as the load testing server, which is called middleware machine in the documentation. One can start the whole infrastructure according to these instructions.
We used the official pretrained ResNet-50 as a reference model. We believe that this model is well known and widely used, and it could be taken like the etalon of the image classification task. This model also has an official implementation in TensorFlow and Torch, respectively. Load testing was done by open-source tool k6.io, which allows parallel firing requests to target service and measures a pretty broad palette of metrics. Basic K6 setup is quite simple as it requires only two input parameters, measuring time and amount of Virtual Users (which is equal to request concurrency). K6 was fed by a random subsample of 50k images from ImageNet LSVRC 2012 Validation Set (6.7GB) for testing. Our use case was to operate a model for a visual search engine. This task, from its nature, can’t fit input image batching (as there are seldom multiple requests that would come within a couple of milliseconds). So we decided to skip batching in measured metrics. All tests were done with batch size 1. The exact configuration of flags for individual servings is clear from the docker-compose definition.
Test scenario 1 :
for all serving methods do
- Run docker container with serving on the serving machine
- Run K6 test with X Virtual Users for 60 seconds on the middleware machine
- Save metrics
- Kill all containers on both machines
- Increase X and goto 1.
Test scenario 2 :
for all serving methods do
- Run docker container with serving on the serving machine
- Run K6 test with X Virtual Users for 60 seconds on the middleware machine
- Save metrics
- Increase X and goto 2.
Evaluation
We chose the request rate and the response time as essential values for serving methods comparison. The first graph shows the dependence of the request rate on the number of virtual users for Torchserve, TensorFlow Serving, and Triton Inference Server with Torch model and TensorFlow Model. Every measure was repeated five times and shown results are averages of medians from examined values.
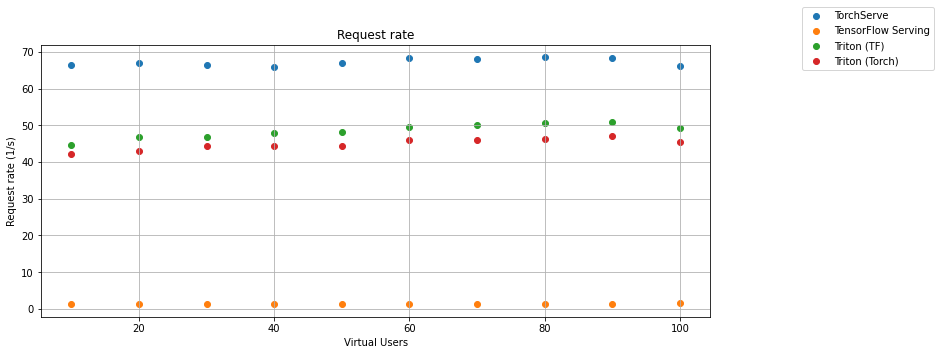
The second chart shows the dependence of the response time on the number of virtual users.
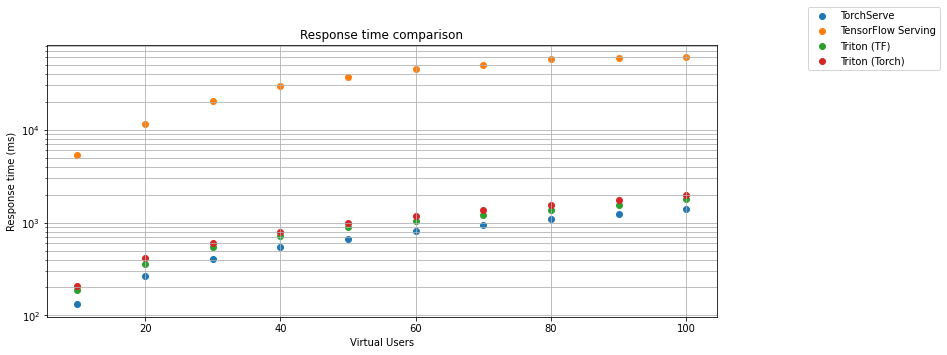
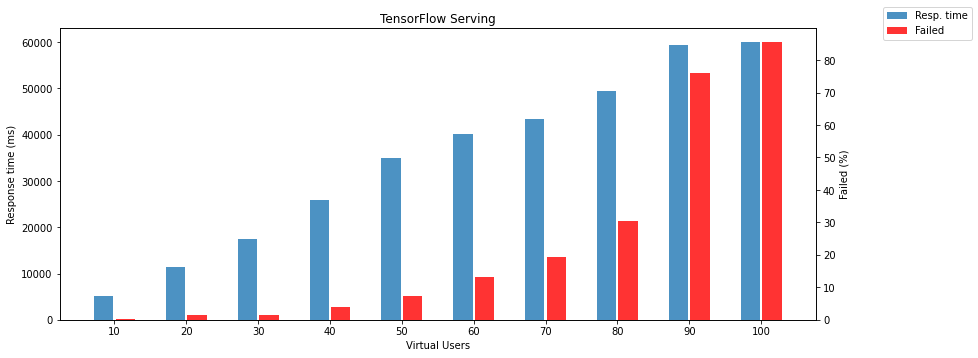
TensorFlow Serving in default configuration is surprisingly slow compared to TorchServe and Triton Inference Server. The biggest surprise is that the TensorFlow model running on Triton Inference Server is almost 40 times faster than the same model on TensorFlow Serving. Even if we optimize TF Serving to allocate all GPU memory by setting per_process_gpu_memory_fraction flag and tensorflow_session_parallelism and tensorflow_intra_op_parallelism. It was still more than 35 times slower than Triton. The TorchServe is faster in response time but less reliable than Triton. We would better not write about the reliability of TensorFlow Serving.
The following two charts show failed responses and response times depending on the number of virtual users.
Note: failed response means that model returns different HTTP status than 200.
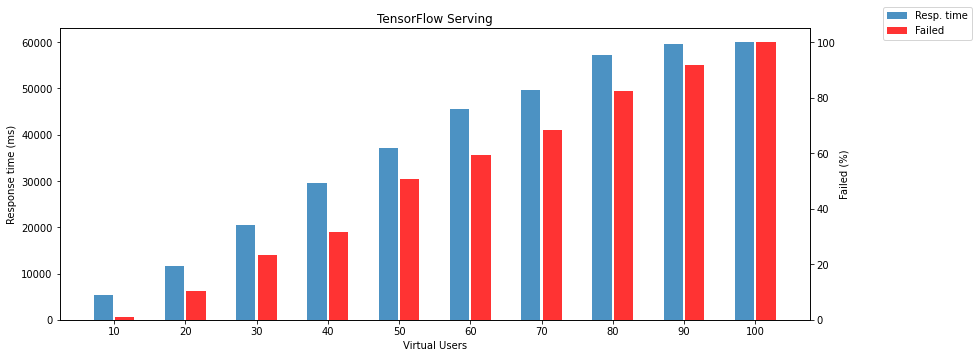
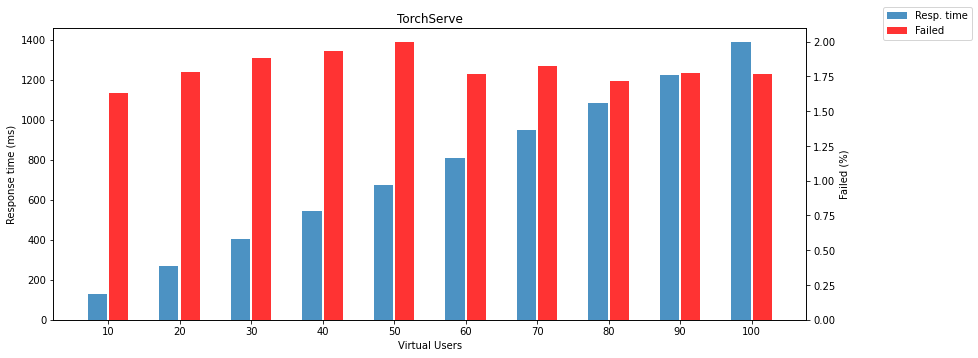
Triton Inference Server is surprisingly reliable. It doesn’t matter how many parallel requests are received. It still returns results without any fail. Obviously, it is useless to show response time and failed responses, so the following chart compares PyTorch and TensorFlow models running on the Triton Inference Server. There is another surprise; the TensorFlow model is slightly faster than PyTorch on Triton.
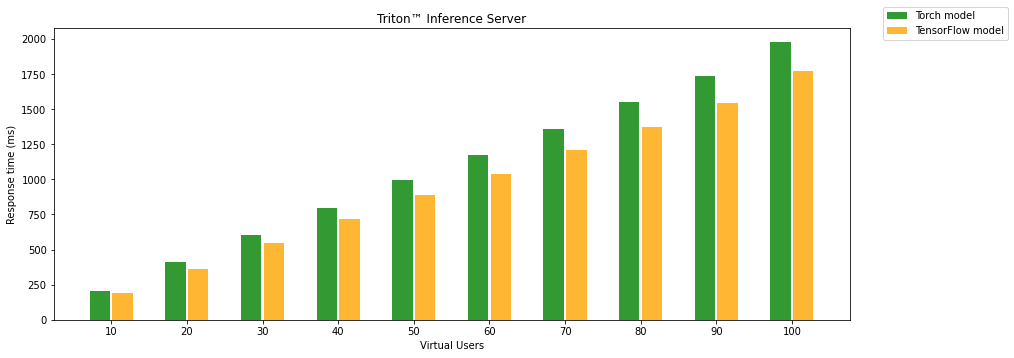
Another test without stopping serving between tests manages something like a model warmup. It is also a bit closer to production because you will run the model and try to keep it running as long as possible. This procedure has a significant impact only on TensorFlow Serving. There is a dramatically decreased amount of failed requests, and TF serving can serve more virtual users.
Conclusion
It has to be said that all tested methods were running in the more or less default configuration, and there is great space for additional configuration and tuning. Anyway, from the test results, we consider TorchServe as the winner. Because it is the fastest and reliable enough to run in production and has the most significant advantage, TorchServe has a simple REST API, which can be called using the curl tool at the end of the day. If you need no failures and heavy load, you should definitely take Triton Inference Server. There is one small piece missing. Triton Inference server needs its own special client, which bends over REST and sends pure binary data in the request body. Simplified, you can not call Triton inference from curl, but it first requires some fiddling with binary data. The worst tested was TensorFlow Serving, but it has to be said that it is the model serving pioneer, and besides, no one uses TF Serving with REST API. From production experiences, we know that TF Serving is much faster with gRPC. Comparison of serving methods with gRPC interface will follow.
Discussion
You can discuss directly on GitHub on this page: https://github.com/Biano-AI/biano-ai.github.io/discussions/3.