A Quantitative Comparison of Serving Platforms for Neural Networks, part 2
In the previous post, we tested REST APIs of TensorFlow serving, TorchServe, and NVIDIA Triton Inference server. In this article, we will look at gRPC APIs. We measured and compared response time, request rate, and failure amount depending on the load.
gRPC
The gRPC is RPC (Remote Procedure Call) initially created by Google. The basic idea of RPC API is very similar to REST API. The client sends a request to the RPC server with or without arguments, and the server does some action. Unlike the REST API, the called method is directly in the URL, where an endpoint does not necessarily contain a method name. The data are in Protocol Buffer (protobuf) format that is translated to binary data before transmission. Moreover, gRPC uses HTTP2, which speeds up communication even more. You can read more about gRPC in official docs.
Test Environment and Setup
For obvious reasons, we have updated a middleware API around serving methods to unify the gRPC interface call for all serving methods. It simplifies load testing configuration, and it is a more production-like configuration. Our middleware has the infer endpoint also for gRPC, which corresponds to Torchserve API.
The infrastructure is completely the same as in the previous article. The first node with GPU was for an observed serving method. The second node was for middleware API and the load testing tool. We used g4dn.xlarge with Deep Learning AMI from AWS for the serving machine and c5.xlarge with standard Ubuntu 20.04 as the load testing server, which is called middleware machine in the documentation. One can start the whole infrastructure according to theseinstructions.
We used the official pretrained ResNet-50 as a reference model. We believe that this model is well known and widely used, and it could be taken like the etalon of the image classification task. This model also has an official implementation in TensorFlow and Torch, respectively. Load testing was done by open-source tool k6.io, which allows parallel firing requests to target service and measures a pretty broad palette of metrics. Basic K6 setup is quite simple as it requires only two input parameters, measuring time and amount of Virtual Users (which is equal to request concurrency). K6 was fed by a random subsample of 50k images from ImageNet LSVRC 2012 Validation Set (6.7GB) for testing. Our use case was to operate a model for a visual search engine. This task, from its nature, can’t fit input image batching (as there are seldom multiple requests that would come within a couple of milliseconds). So we decided to skip batching in measured metrics. All tests were done with batch size 1. The exact configuration of flags for individual servings is clear from the docker-compose definition.
Test scenario 1 :
for all serving methods, do
- Run docker container with serving on the serving machine
- Run K6 test with X Virtual Users for 60 seconds on the middleware machine
- Save metrics
- Kill all containers on both machines
- Increase X and goto 1.
Test scenario 2 :
for all serving methods, do
- Run docker container with serving on the serving machine
- Run K6 test with X Virtual Users for 60 seconds on the middleware machine
- Save metrics
- Increase X and goto 2.
Evaluation
We chose the request rate and the response time as essential values for serving methods comparison. The first graph shows the dependence of the request rate on the number of virtual users for Torchserve, TensorFlow Serving, and Triton Inference Server with Torch model and TensorFlow Model.
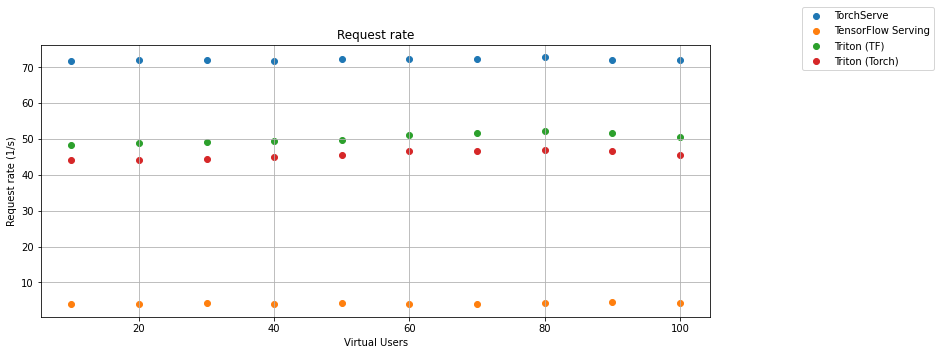
The second chart shows the dependence of the response time on the number of virtual users.
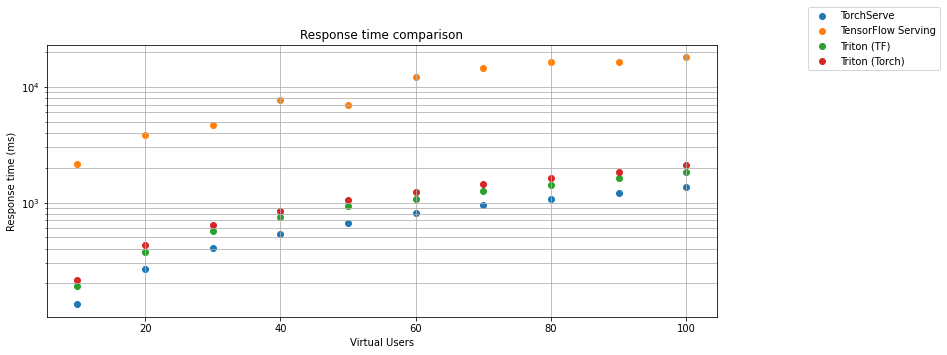
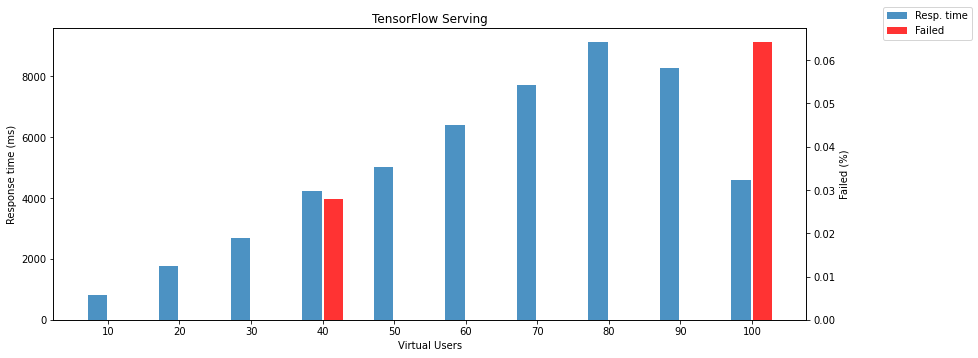
TensorFlow Serving gRPC interface in default configuration is still much slower than TorchServe and Triton Inference Server and a lot faster than REST API. The biggest surprise is that the TensorFlow model running on Triton Inference Server is still almost 30 times faster than the same model on TensorFlow Serving. Even if we optimize TF Serving to allocate all GPU memory by setting per_process_gpu_memory_fraction flag and tensorflow_session_parallelism and tensorflow_intra_op_parallelism. It was still more than 25 times slower than Triton. The TorchServe is faster in response time but less reliable than Triton. The gRPC interface of TensorFlow serving is much more reliable than the REST API. The results are so good that they can be compared with TorchServe from a fail point of view. In the case of speed, TorchServe is still miles away from TensorFlow serving.
The following two charts show failed responses and response times depending on the number of virtual users.
Note: failed response means that the model returns different HTTP status than 200.
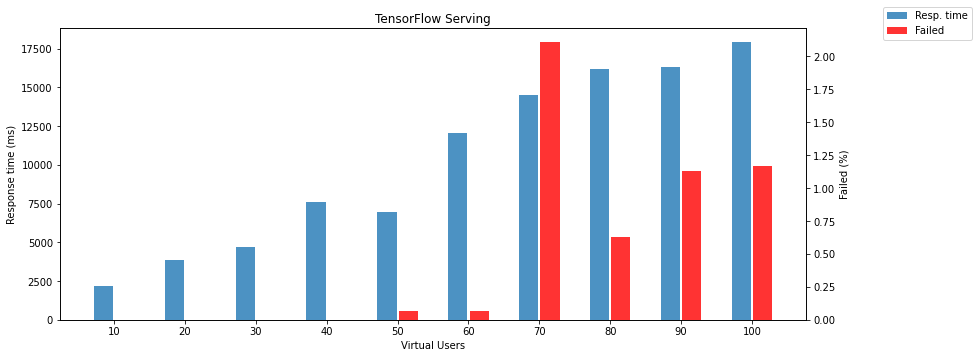
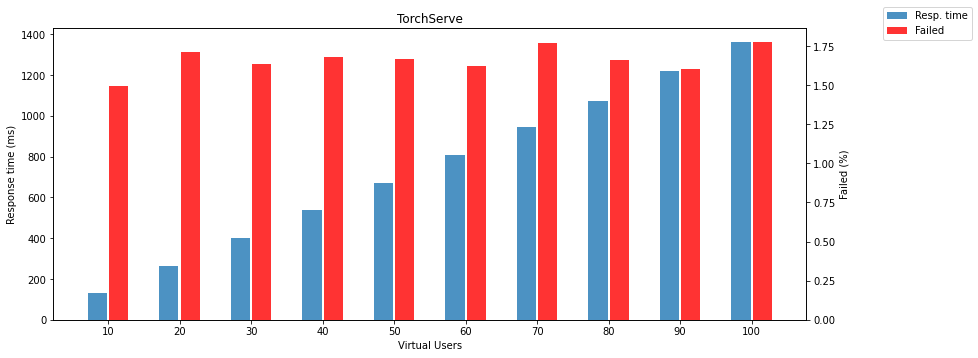
The gRPC interface of the Triton Inference Server is still as reliable and fast as REST API. It doesn’t matter how many parallel requests are received. It still returns results without any fail. It is useless to show response time and failed responses, so the following chart compares PyTorch and TensorFlow models running on the Triton Inference Server. There is another surprise; the TensorFlow model is again slightly faster than PyTorch on Triton.
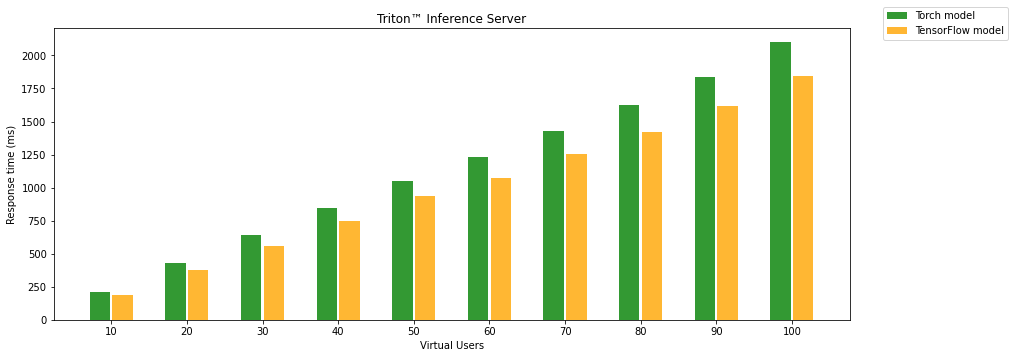
Another test without stopping serving between tests manages something like a model warmup. It is also a bit closer to production because you will run the model and keep it running as long as possible. This procedure has a positive impact only on TensorFlow Serving. The amount of failed requests is even lower than in the previous test.
Conclusion
It has to be said that all tested methods were running in the more or less default configuration, and there is a great space for additional configuration and tuning. Anyway, from the test results, we still consider TorchServe as a winner. Because it is the fastest and reliable enough to run in production and has the most significant advantage, TorchServe has a simple REST API, even as fast and as reliable as gRPC API. TensorFlow Serving is much more reliable and faster with the gRPC interface, but still, there are better ways. If you need no failures and heavy load, you should take Triton Inference Server. The gRPC is slightly faster than the REST API, but the difference is negligible. There is just one inconvenience. Triton Inference Server needs its special client. That’s why you can not call Triton inference from curl and, for example, do the simple periodic health check. If you don’t mind, the choice is clear.
Discussion
You can discuss directly on Github on this page: https://github.com/Biano-AI/biano-ai.github.io/discussions/3.